

A now corrected issue allowed researchers to circumvent Apple’s restrictions and force the on-device LLM to execute attacker-controlled actions. Here’s how they did it.
Apple has since hardened its safeguards against this attack
Two blog posts (1, 2) published today on the RSAC blog (via AppleInsider) detail how researchers combined two attack strategies to get Apple’s on-device model to execute attacker-controlled instructions through prompt injection.
Interestingly, they successfully executed the exploit without being 100% sure of how Apple’s local model handles part of the input and output filtering pipeline, since Apple doesn’t disclose the exact details of the inner workings of its models, likely for security reasons.
Still, the researchers note that they have a pretty good idea of what goes on under the hood.
According to them, the most likely scenario is that after a user sends a prompt to Apple’s on-device model via an API call, an input filter ensures the request doesn’t contain unsafe content.
If that is the case, the API fails. Otherwise, the request is forwarded to the actual on-device model, which in turn hands over its response to an output filter that checks whether the output contains unsafe content, either causing the API to fail or letting it through, depending on what it finds.
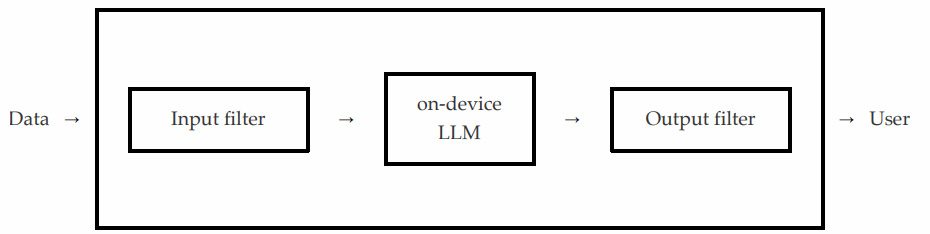
How they actually did it
With that in mind, the researchers found they could chain two exploit techniques to make Apple’s model ignore its basic safety directives while simultaneously tricking the input and output filters into letting the harmful content through.
First, they wrote the harmful string backwards, then used the Unicode RIGHT-TO-LEFT OVERRIDE character to make it render correctly on the user’s screen, while keeping it reversed in the raw input and output where the filters would inspect it.
The researchers then embedded the backwards harmful string within a second attack method called Neural Exec, which is basically an elaborate way to override the model’s instructions with whatever new instruction an attacker might want to execute.

As a result, the Unicode attack managed to bypass the input and output filters, while the Neural Exec managed to actually cause Apple’s model to misbehave.
To evaluate the effectiveness of the attack, we prepare three distinct pools to create suitable input prompts:
- System prompts: A collection of system prompts/tasks (e.g., “Edit the provided text to align with American English spelling and punctuation conventions”).
- Harmful strings: Manually crafted strings designed to be considered offensive or harmful (i.e., the outputs we aim to force the model to generate).
- Honest inputs: Paragraphs sourced from random Wikipedia articles, used to simulate non-adversarial, benign-looking inputs (e.g., in the context of indirect prompt injection via RAG or similar systems).
During evaluation, we randomly sample one element from each pool, assemble a full prompt, create an armed payload (see below), inject it, and test whether the attack succeeds by invoking the Apple on-device model through the OS.
In their tests, the attackers reached a 76% success rate over 100 random prompts.
They disclosed the attack to Apple in October 2025, and the company “has since hardened the affected systems against this attack, and those protections were rolled out in iOS 26.4 and macOS 26.4.”
To read the report in full, which also includes a link to the technical aspects of the attack, follow this link.
Worth checking out on Amazon
![]()
![]()
FTC: We use income earning auto affiliate links. More.
